 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVysics: Object Reconstruction Under Occlusion by Fusing Vision and Contact-Rich Physics
Apr 25, 2025



We introduce Vysics, a vision-and-physics framework for a robot to build an expressive geometry and dynamics model of a single rigid body, using a seconds-long RGBD video and the robot's proprioception. While the computer vision community has built powerful visual 3D perception algorithms, cluttered environments with heavy occlusions can limit the visibility of objects of interest. However, observed motion of partially occluded objects can imply physical interactions took place, such as contact with a robot or the environment. These inferred contacts can supplement the visible geometry with "physible geometry," which best explains the observed object motion through physics. Vysics uses a vision-based tracking and reconstruction method, BundleSDF, to estimate the trajectory and the visible geometry from an RGBD video, and an odometry-based model learning method, Physics Learning Library (PLL), to infer the "physible" geometry from the trajectory through implicit contact dynamics optimization. The visible and "physible" geometries jointly factor into optimizing a signed distance function (SDF) to represent the object shape. Vysics does not require pretraining, nor tactile or force sensors. Compared with vision-only methods, Vysics yields object models with higher geometric accuracy and better dynamics prediction in experiments where the object interacts with the robot and the environment under heavy occlusion. Project page: https://vysics-vision-and-physics.github.io/
Instance-Agnostic Geometry and Contact Dynamics Learning
Sep 28, 2023



This work presents an instance-agnostic learning framework that fuses vision with dynamics to simultaneously learn shape, pose trajectories, and physical properties via the use of geometry as a shared representation. Unlike many contact learning approaches that assume motion capture input and a known shape prior for the collision model, our proposed framework learns an object's geometric and dynamic properties from RGBD video, without requiring either category-level or instance-level shape priors. We integrate a vision system, BundleSDF, with a dynamics system, ContactNets, and propose a cyclic training pipeline to use the output from the dynamics module to refine the poses and the geometry from the vision module, using perspective reprojection. Experiments demonstrate our framework's ability to learn the geometry and dynamics of rigid and convex objects and improve upon the current tracking framework.
Autonomous Navigation for Quadrupedal Robots with Optimized Jumping through Constrained Obstacles
Jul 01, 2021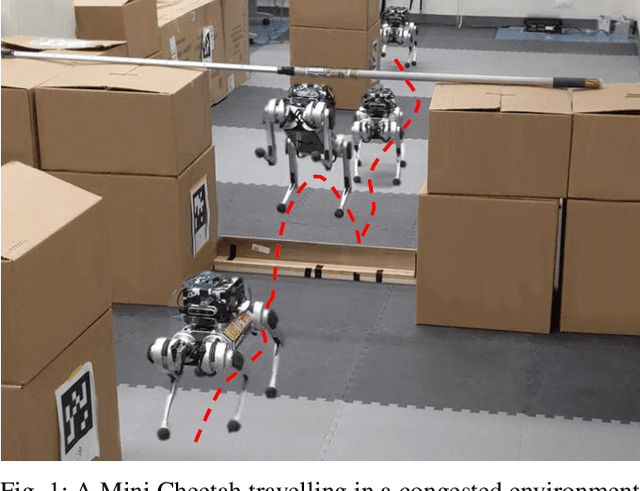

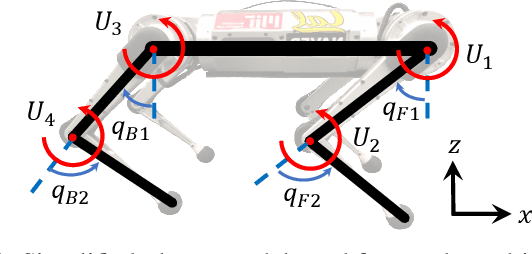
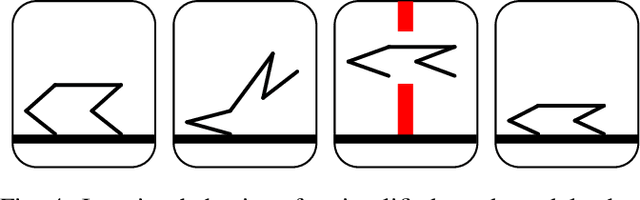
Quadrupeds are strong candidates for navigating challenging environments because of their agile and dynamic designs. This paper presents a methodology that extends the range of exploration for quadrupedal robots by creating an end-to-end navigation framework that exploits walking and jumping modes. To obtain a dynamic jumping maneuver while avoiding obstacles, dynamically-feasible trajectories are optimized offline through collocation-based optimization where safety constraints are imposed. Such optimization schematic allows the robot to jump through window-shaped obstacles by considering both obstacles in the air and on the ground. The resulted jumping mode is utilized in an autonomous navigation pipeline that leverages a search-based global planner and a local planner to enable the robot to reach the goal location by walking. A state machine together with a decision making strategy allows the system to switch behaviors between walking around obstacles or jumping through them. The proposed framework is experimentally deployed and validated on a quadrupedal robot, a Mini Cheetah, to enable the robot to autonomously navigate through an environment while avoiding obstacles and jumping over a maximum height of 13 cm to pass through a window-shaped opening in order to reach its goal.